docker与k8s的基本介绍
一、Docker
1. 什么是docker
Docker是一个开源的引擎,可以轻松地为任何应用创建一个轻量级的、 可移植的、自给自足的容器。这里需要注意,Docker本身并不是容器,它是创建容器的工具,是应用容器引擎。
2. 为什么使用docker
- 更快的将会和部署
- 更高效的虚拟化
- 更轻松的迁移和扩展
- 更简单的管理
- 对比传统虚拟机的更大的优势:启动秒级/硬盘使用MB/性能好/单机支持上千个容器
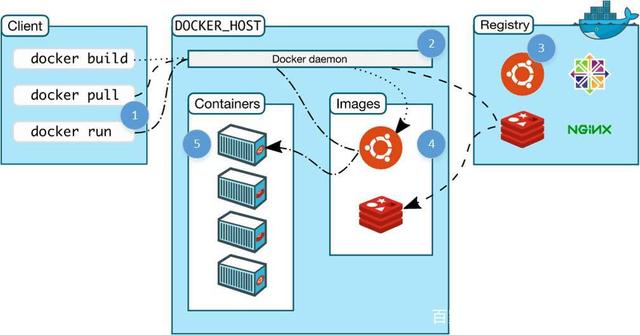
3. docker三大核心概念
3.1 镜像(Image)
镜像,从认识上简单的来说,就是面向对象中的类,相当于一个模板。从本质上来说,镜像相当于一个文件系统。Docker 镜像是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。镜像不包含任何动态数据,其内容在构建之后也不会被改变。3.2 容器(Container)
容器,从认识上来说,就是类创建的实例,就是依据镜像这个模板创建出来的实体。容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的命名空间。因此容器可以拥有自己的root 文件系统、自己的网络配置、自己的进程空间,甚至自己的用户ID 空间。容器内的进程是运行在一个隔离的环境里,使用起来,就好像是在一个独立于宿主的系统下操作一样。3.3 仓库(Repository)
仓库是集中存放镜像文件的场所。有时候会把仓库和仓库注册服务器( Registry)混为一谈,并不严格区分。 实际上,仓库注册服务器上往往存放着多个仓库,每个仓库中又包含了多个镜像,每个镜像有不同的标签( tag)。仓库分为公开仓库( Public)和私有仓库( Private) 两种形式。
最大的公开仓库是 Docker Hub,存放了数量庞大的镜像供用户下载。 国内的公开仓库包括 Docker Pool 等,可以提供大陆用户更稳定快速的访问。
当然,用户也可以在本地网络内创建一个私有仓库。当用户创建了自己的镜像之后就可以使用 push 命令将它上传到公有或者私有仓库,这样下次在另外一台机器上使用这个镜像时候,只需要从仓库上 pull 下来就可以了。4. docker基础命令
docker info
docker version
docker search
docker pull 拉取镜像
docker run 运行容器
eg: docker run –it centos:latest /bin/bash
-i 表示启动一个可交互的容器
-t 表示让docker分配一个伪终端并绑定到容器的标准输入上,
Centos:latest 表示我们要运行得镜像
/bin/bash 表示我们启动容器的时候要运行得命令
docker images 列出所有镜像
docker ps 查看在运行得容器 docler ps –a 查看所有容器
docker stop/start/restart 容器停止启动重启
docker rmi 删除镜像
docker rm 删除容器
docker tag标记本地镜像,将其归入某一仓库
5. dockerfile
Dockerfile 是一个由一堆命令+参数构成的脚本,使用 docker build 即可执行脚本构建镜像,自动的去做一些事,主要用于进行持续集成
5.1 dockerfile语法
<1> FROM:
1.FROM指定一个基础镜像, 一般情况下一个可用的 Dockerfile一定是 FROM 为第一个指令。至于image则可以是任何合理存在的image镜像。
2.FROM 一定是首个非注释指令 Dockerfile。
3.FROM 可以在一个 Dockerfile 中出现多次,以便于创建混合的images。
4.如果没有指定 tag ,latest 将会被指定为要使用的基础镜像版本。
<2> MAINTAINER:
这里是用于指定镜像制作者的信息。
<3> RUN:用来修改镜像的命令,常用来安装库、程序以及配置程序。一条RUN指令执行完毕后,会在当前镜像上创建一个新的镜像层,接下来对的指令会在新的镜像上继续执行。
<4> ENV:
1.ENV指令可以用于为docker容器设置环境变量
2.ENV设置的环境变量,可以使用 docker inspect命令来查看。同时还可以使用docker run –env =来修改环境变量。
<5> WORKDIR: 为接下来执行的指令指定一个新的工作目录,这个目录可以使绝对目录,也可以是相对目录
<6> COPY:COPY 将文件从路径 复制添加到容器内部路径 。
必须是想对于源文件夹的一个文件或目录,也可以是一个远程的url, 是目标容器中的绝对路径。
<7> ADD:
ADD 将文件从路径 复制添加到容器内部路径 。
向新镜像中添加文件,这个文件可以是一个主机文件,也可以是一个网络文件,也可以使一个文件夹。
第一个参数:源文件(夹),如果是相对路径,它必须是相对于Dockerfile所在目录的相对路径。如果是URL,会先下载下来,再添加到镜像里去。
第二个参数:目标路径。如果源文件是主机上zip或者tar形式的压缩文件,Docker会先解压缩,然后将文件添加到镜像的指定位置。如果源文件是一个通过URL指定的网络压缩文件,则不会解压。
<8> VOLUME:创建一个可以从本地主机或其他容器挂载的挂载点,一般用来存放数据库和需要保持的数据等。
<9> EXPOSE : 用来指明容器内进程对外开放的端口,多个端口之间使用空格隔开。
<10> CMD:用来设置启动容器时默认运行的命令
5.2 实例
Dockerfile构建nginx
首先建立一个自己的目录
mkdir /feng
在里面放入nginx的tar包以及写好的Dockerfile
Cat Dockerfile:
1 | From docker.io/centos |
–prefix=/usr/local/nginx \指定安装路径
–user –group \指定nginx的所有者,所属者
–with-http_stub_status_module \声明启用service status页,默认不启用
–with-http_ssl_module \启用ssl模块,以支持https请求
EXPOSE 80
CMD [“nginx”,”-g”,”deamon off;”]
然后开始构建镜像
1 | Docker built -t nginxfeng #(指定容器名字) |
接着运行nginx镜像
1 | docker run -d -p 81:80 --name test -v /feng/index.html:/usr/local/nginx/html/index.html nginxfeng |
可以看到访问nginx 返回的是我们制定的index.html 内容 说明nginx启动成功。
二、Kubernetes
1. k8s 介绍
K8S,就是基于容器的集群管理平台,它的全称,是kubernetes。如果你曾经用过Docker容器技术部署容器,那么可以将Docker看作Kubernetes内部使用的低级别组件。Kubernetes 不仅仅支持Docker,还支持Rocket,这是另一种容器技术。
使用kubernetes可以:
- 自动化容器的部署和复制;
- 随时扩展或收缩容器规模;
- 将容器组织成组,并且提供容器间的负载均衡;
- 很容易地升级应用程序容器的新版本;
- 提供容器弹性,如果容器失效就替换它,等等
2. k8s 的主要概念
- Pods
Pod是kubernetes最重要也最基本的概念,如图所示是Pod的组成示意图,我们看到每个Pod都有一个特殊的被称为“根容器”的Pause容器对应的镜像属于Kubernetes的平台的一部分,除了Pause容器,每个Pod还包含一个或多个紧密相关的用户业务容器
每个pod由一个根容器的pause容器,其他是业务容器。
k8s为每个pod分配了唯一的IP地址,一个pod里的多个容器共享pod IP。pod其实有两种类型:普通的pod和静态pod,后者比较特殊,它并不存放在etcd存储中,而是存放在某个具体的Node上的一个具体文件中,并且只在此Node上启动运行。而普通的pod一旦被创建,就会被放入etcd中存储。随后被master调度到某个具体的Node上并进行绑定,随后该pod被对应的Node上的kubelet进程实例化成一组相关的docker容器并启动起来。
每个pod都可以对其使用的服务器上的计算资源设置限额,当前可以设置限额的源有CPU和memory两种。其中CPU的资源单位为CPU的数量。
一般而言,一个CPU的配额已经算是相当大的一个资源配额,所以在k8s中,通常以千分之一的CPU配额为最小单位,以m来表示,通常一个容器的CPU配额为100-300m,即占用0.1-0.3个CPU。这个配额是个绝对值,不是占比。
在k8s中,一个计算资源进行配额限定需要设定两个参数:
requests,资源的最小申请量,系统必须满足要求
- Services
Service是Kubernetes里最核心的资源对象之一,Service定义了一个服务的访问入口地址,前端的应用(Pod)通过这个入口地址访问其背后的一组由Pod副本组成的集群实力。 Service与其后端Pod副本集群之间则是通过Label Selector来实现”无缝对接”。而RC的作用实际上是保证Service 的服务能力和服务质量处于预期的标准
每个pod会被分配一个独立的IP地址,也就是每个pod都提供一个独立的endpoint(IP+port)以被访问,那多个pod如何被客户端访问呢,k8s通过运行在每个Node上的kube-proxy进程,负责将对service的请求转发到后端某个pod实例上,也就实现了类似负载均衡器的功能,至于具体转发到哪个pod,则由负载均衡器的算法所决定。并且service不是共用一个负载均衡器的IP地址,而是每一个service分配了一个全局唯一的虚拟IP,这样每个服务就变成了具有唯一IP的通信节点,服务调用也就变成了最为基础的TCP通信问题。
pod的Endpoint地址会随着Pod的销毁和重新创建而发生改变,因为新的Pod地址与之前的旧的Pod不同。而Service一旦被创建,Kubernetes就会自动为它分配一个可用的Cluster IP,而且在Service的整个声明周期内,它的Cluster IP不会发生改变。所以只要将Service的name与Service的Cluster IP地址做一个DNS域名映射即可解决问题。
k8s的服务发现机制:每个service都有一个唯一的cluster IP以及唯一的名字,而名字是由开发者自己定义的,部署的时候也没必要改变,所以完全可以固定在配置中,接下来的问题 就是如何通过service的名字找到对应的cluster IP。外部系统访问service的问题:
k8s中有三种IP:
a,Node IP:node节点的IP地址
b,Pod IP:pod的IP地址
c,cluster IP:service IP首先,Node IP是k8s集群中每个节点的物理网卡的IP地址,这是一个真实存在的物理网络,所有属于这个网络的服务器之间都能直接通信,不管属不属于k8s集群。这也表明了k8s集群之外的节点访问k8s集群之内的某个节点后者TCP/IP服务的时候,必须要通过Node IP通信。
其次,pod IP是每个Pod的IP地址,它是根据docker网桥的IP地址段进行分配的,通常是一个虚拟的二层网络,因此不同pod之间的通信就是通过Pod IP所在的虚拟二层网络进行通信的。而真实的TCP/IP流量则是通过Node IP所在的物理网卡流出的。
Cluster IP,它是一个虚拟IP,但更像是一个伪造的IP网络
(1)Cluster IP仅仅作用于Kubernetes Service对象,并由Kubernetes管理和分配IP地址(来源于Cluster IP地址池)
(2)Cluster IP无法被Ping,因为没有一个”实体网络对象”来响应
(3)在Kubernetes集群内,Node IP、Pod IP、Cluster IP之间的通信,采用的是Kubernetes自己设计的特殊路由规则
- Replication Controllers
Replication Controller确保任何时候Kubernetes集群中有指定数量的Pod副本(replicas) 在运行,如果少于指定数量的Pod副本(replicas ),Replication Controller会启动新的Container,反之会“杀死”多余的以保证数量不变。Replication Controller使用预先定义的Pod模板创建pods,一旦创建成功,Pod模板和创建的pods没有任何关联,可以修改Pod模板而不会对已创建pods有任何影响,也可以直接更新通过Replication Controller创建的pods。
- Labels
一个label是一个key=value的键值组合,然后可以通过label selector(标签选择器)查询和筛选拥有某些label的资源对象。
(Label 相当于我们熟悉的标签,给某个资源对象定义一个Label,就相当于给它打了一个标签,随后可以通过Label Selector 标签选择器 查询和筛选有某些Label的资源对象。Kubernetes通过这种方式实现了类似SQL的简单又通用的对象查询机制)。label的重要使用场景:
kube-controller进程通过资源对象RC上定义的label selector来筛选要监控的pod的数量,从而实现全自动控制流程。
kube-proxy进程通过service的label selector来选择对应的pod,自动建立起每个service到对应pod的请求转发路由表。从而实现service的智能负载均衡机制。
- HPA(horizontal Pod Autoscaler Pod横向自动扩容)
通过手动执行kubectl scale命令,可以通过RC实现pod扩容。
HPA,pod横向自动扩容,实现原理是通过追踪分析RC控制的所有目标Pod的负载变化情况,来确定是否需要针对性地挑战目标pod的副本数。
有两种方式作为pod负载的度量指标。
<1>CPU utilization percentage
<2>应用程序自定义的度量指标,比如服务在每秒内的相应的请求数。
CPU utilization percentage是一个算术平均值,目标pod所有副本自身的CPU利用率的平均值。一个Pod自身的CPU利用率是该Pod当前CPU使用量除以它的Pod request的值。比如当我们定义一个Pod的pod request为0.4,而当前pod的cpu使用量为0.2,则使用率为50%。如此可以得出一个平均值,如果某一个时刻CPU utilization percentage超过80%,则表示当前副本数不够,需要进行扩容.
- namespace命名空间
大多数情况下用于实现多租户的资源隔离,namespace通过将集群内部的资源对象分配到不同的namespace中,形成逻辑上分组的不同项目、小组,便于不同的分组在共享使用整个集群的资源的同时还能被分别管理。
namespace的定义很简单,如下所示的yaml定义了名为development的namespace
apiVersion: v1
kind: Namespace
metadata:
name: development
1
一旦创建了Namespace,我们在创建资源对象时就可以指定这个资源对象属于哪个namespace,比如下面,定义了名为busybox的Pod,放入development这个namespace里:
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: development
3. k8s 架构
一个K8S系统,通常称为一个K8S集群(Cluster)
这个集群主要包括两个部分:
- 一个Master节点(主节点)
- 一群Node节点(计算节点)
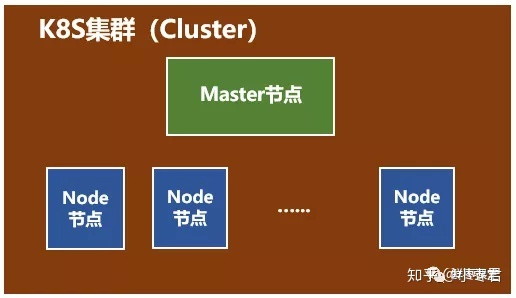
一看就明白:Master节点主要还是负责管理和控制。Node节点是工作负载节点,里面是具体的容器。
3.1 Master节点
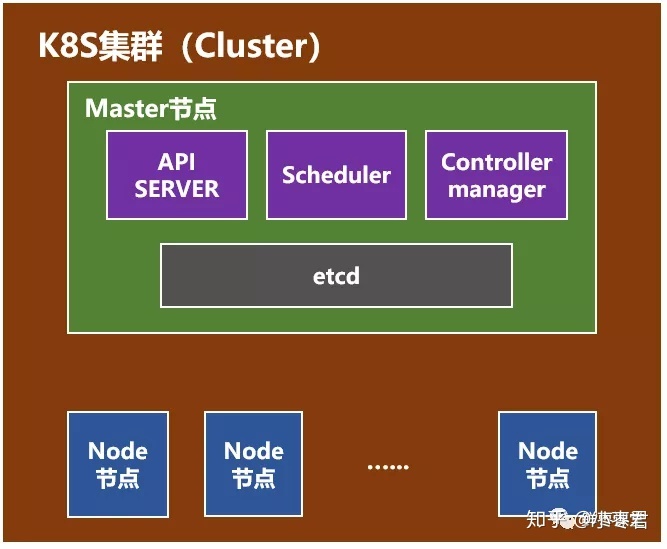
Kubernetes 里的Master指的是集群控制节点,每个Kubernetes集群里需要有一个Master节点来负责整个集群的管理和控制,基本上Kubernetes所有的控制命令都发给它,它负责具体的执行过程,我们后面执行的所有命令基本上都是在Master节点上运行的。如果Master宕机或不可用,那么集群内容器的管理都将失效
Master节点包括API Server、Scheduler、Controller manager、etcd。
k8s API server(kube-apiserver),提供了HTTP Rest接口的关键服务进程,是所有资源的增删改查的唯一入口,也是集群集群控制的入口进程。kubectl的命令会调用到api server,来实现资源的增删查改。
kube-controller-manager,k8s所有资源对象的自动化控制中心。
kube-scheduler,pod调度进程。
etcd服务,因为k8s里所有资源对象的数据全部是保存在etcd中的,etcd是一个高可用的键值存储系统,主要用于共享配置和服务发现
3.2 Node节点
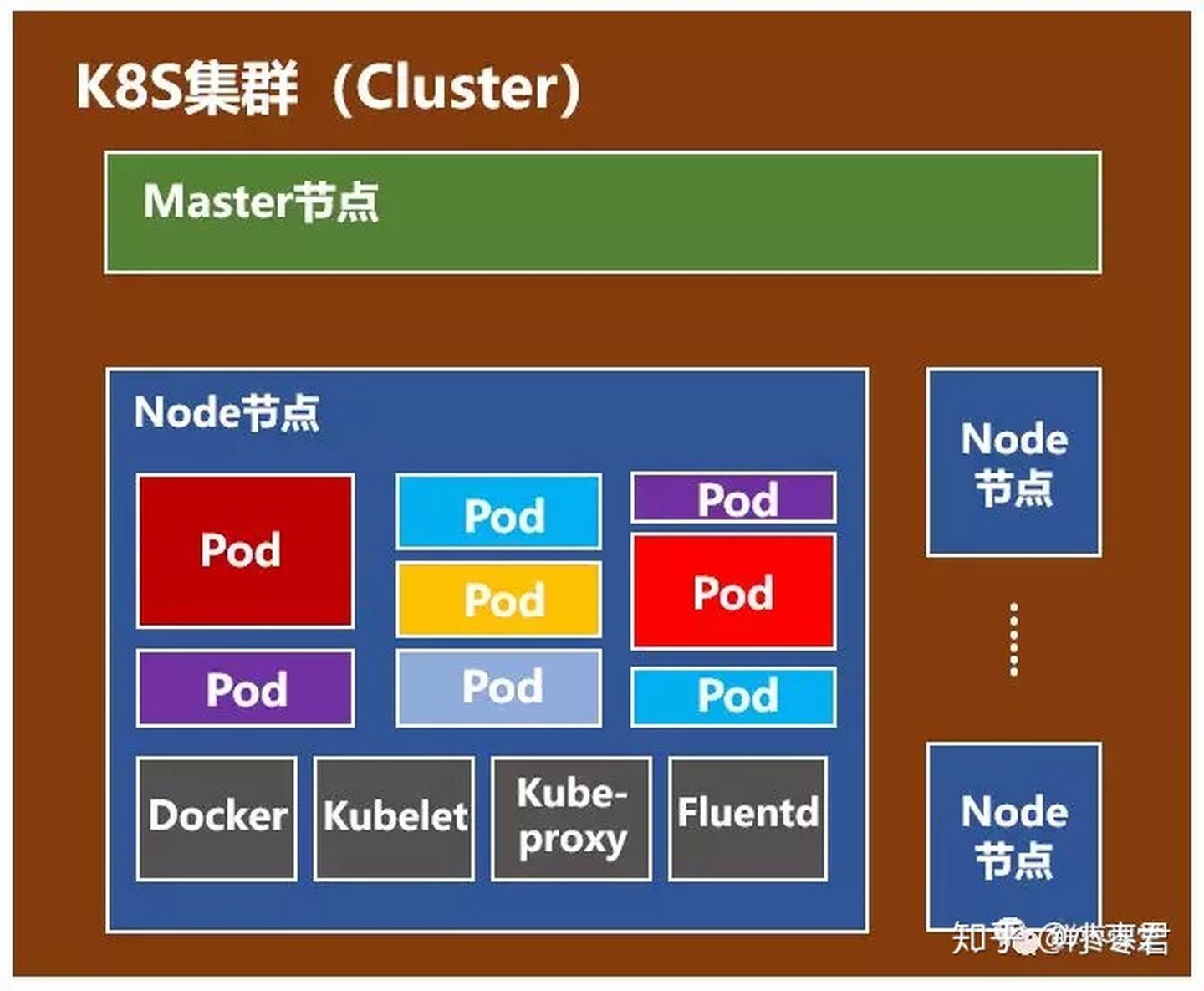
除了Master,集群中其他机器被称为Node节点,每个Node都会被Master分配一些工作负载docker容器,当某个Node宕机时,其上的工作负载会被Master自动转移到其他节点上去
Node节点包括Docker、kubelet、kube-proxy、Fluentd、kube-dns(可选),还有就是Pod。Pod是Kubernetes最基本的操作单元。一个Pod代表着集群中运行的一个进程,它内部封装了一个或多个紧密相关的容器。除了Pod之外,K8S还有一个Service的概念,一个Service可以看作一组提供相同服务的Pod的对外访问接口。
Docker,不用说了,创建容器的。
Kubelet,主要负责监视指派到它所在Node上的Pod,包括创建、修改、监控、删除等。
Kube-proxy,实现Kubernetes Service的通信与负载均衡机制的重要组件。
Fluentd,主要负责日志收集、存储与查询。
查看当前nodes:kubectl get nodes
然后通过下面命令查看某个node的详细信息:kubectl describe node
3.3 Master与Node工作内容
在集群管理方面,Kubernets将集群中的机器划分为一个Master节点和一群工作节点(Node),其中,在Master节点上运行着集群管理相关的一组进程kube-apiserver、kube-controller-manager和kube-scheduler,这些进程实现了整个集群的资源管理、Pod调度、弹性收缩、安全控制、系统监控和纠错等管理功能,并且都是全自动完成的。Node作为集群中的工作节点,运行真正的应用程序,在Node上Kubernetes管理的最小运行单元是Pod。Node上运行着Kubernetes的kubelet、kube-proxy服务进程,这些服务进程负责Pod创建、启动、监控、重启、销毁、以及实现软件模式的负载均衡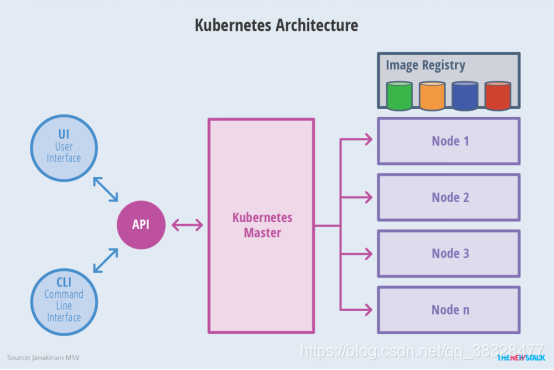
4. kubernetes基础命令
kubectl get
kubectl get命令用来获取资源信息列表,可用来查看pod是否健康,当前的运行状态,重启了几次,生命周期等,是最常用的命令之一kubectl get pod
获取pod资源列表,默认获取default命名空间kubectl get pod -n kube-system
获取kube-system命名空间的pod资源列表kubectl get pod –all-namespaces
获取所有命名空间的pod资源列表kubectl get pod -n kube-system kube-apiserver-k8s-01
获取kube-system命名空间中指定的pod:kube-apiserver-k8s-01的信息
当查看某个具体的pod时,必须指明该pod所在的命名空间,像–all-namespaces参数是不能使用的kubectl get pod -n kube-system kube-apiserver-k8s-01 -o wide
获取kube-system命名空间中指定的pod:kube-apiserver-k8s-01的信息,并且展示更多信息,包括pod ip,所在节点等信息kubectl get pod -n kube-system kube-apiserver-k8s-01 -o yaml
获取kube-system命名空间中指定的pod:kube-apiserver-k8s-01的信息,并且以yaml格式展示pod详细信息kubectl get pod -n kube-system kube-apiserver-k8s-01 -o json
获取kube-system命名空间中指定的pod:kube-apiserver-k8s-01的信息,并且以json格式展示pod详细信息kubectl get pod –all-namespaces –watch
监控pod资源的变化上述命令中的pod为kubernetes集群中的一种资源对象,其它资源对象,例如:deployment、deamonset、endpoint、ingress、services、secrets等等,都可以用get命令,全部的资源对象详见这里
kubectl describe
打印所选资源的详细描述信息,当pod启动异常的时候也可以用该命令排查问题kubectl describe -n kube-system pod kube-apiserver-k8s-01
描述pod:kube-apiserver-k8s-01的详细信息kubectl describe -n kube-system secrets kubernetes-dashboard-token-9mvxp
描述secrets详细信息,例如该命令可查询登录dashboard所需的token信息kubectl exec
与docker exec命令一样,kubectl exec 也是用来进入容器内部的kubectl exec -it -n kube-system kube-apiserver-k8s-01 sh
进入kube-system命名空间下的kube-apiserver-k8s-01容器内部
仅当pod内只有一个容器的时候适用kubectl exec -it -n kube-system calico-node-rw4c2 -c install-cni sh
-it:开启虚拟终端tty,并将标准输入传入容器中
-i, –stdin=false: Pass stdin to the container
-t, –tty=false: Stdin is a TTY
当pod中有多个容器,需要进入指定的容器时适用,比上一条命令多了-c container_namecontainer_name可以通过kubectl describe命令获得
kubectl describe pod calico-node-rw4c2 -n kube-system | grep -B 1 “Container ID”kubectl logs
kubectl logs用来查看容器的日志,在定位问题时非常有用
kubectl logs -n kube-system -f –tail 10 kube-apiserver-k8s-01
-f: 动态打印日志
–tail 10: 打印最后10行日志,不加该参数时默认会打印全部的日志,在日志非常多的时候非常有用kubectl scale
kubectl scale用来对deployement、replicaset、statefulset等资源进行伸缩
kubectl scale deployment -n kube-system –replicas=2 kubernetes-dashboard
–replicas=2: 指定副本数量为2
先设置replicas=0,再设置replicas=1可实现pod重启操作kubectl apply
通过传入文件名或者标准输入来创建资源或配置kubectl apply -f .
创建或更新当前目录所有的yaml文件描述的配置或资源kubectl apply -f /home/agms/
创建或更新指定目录所有的yaml文件描述的配置或资源kubectl apply -f /home/agms/a.yaml
创建或更新指定yaml文件描述的配置或资源kubectl delete
kubectl delete -f .
删除当前目录所有的yaml文件描述的配置或资源kubectl delete -f /home/agms/
删除指定目录所有的yaml文件描述的配置或资源kubectl delete -f /home/agms/a.yaml
删除指定yaml文件描述的配置或资源kubectl delete nodes k8s-01
按照节点名删除集群中的节点(慎用)kubectl explain*
列出受支持资源的字段、版本,各字段的描述、类型等,在编写yaml文件时非常有用kubectl explain deployment.spec
描述deployment资源的spec字段kubectl create
通过命令行创建kubernetes资源或配置信息kubectl create namespace fpi-inc
创建一个fpi-inc的命名空间一般建议通过kubectl apply的方式来进行资源或配置的创建
参考
 wechat
wechat alipay
alipay